PHP Fatal Error Memory exhausted beim search-index nach C__CATG__ADRESS
-
Hallo,
in der Hoffnung dass hier jemand eine Idee hat erläutere ich mal mein Problem:
Die i-doit-jobs Datei wird täglich früh morgens per Cronjob ausgeführt - funktioniert.
Manuell hinzugefügt hatte ich den LDAP-Sync Befehl - funktioniert.Neuerdings bemerkten wir öfters dass der LDAP-Sync nicht automatisch gelaufen ist.
Nach manuellem ausführen der i-doit-jobs Datei kam beim Befehl search-index beim Punkt "C__CATG__ADDRESS" der Fehler:Finished reading 13 rows Start mapping 13 rows to 117 documents for "Anschrift" (C__CATG__ADDRESS) 50 of 117 documents were skipped! Start inserting documents Finished inserting documents! Start inserting documents Finished inserting documents! PHP Fatal error: Allowed memory size of 2147483648 bytes exhausted (tried to allocate 20480 bytes) in /var/www/html/src/classes/components/isys_component_database_mysqli.class.php on line 275Wie in der Fehlermeldung ggf. ersichtlich ist, habe ich durch einen Tipp des i-doit-Supports den Wert memory_limit in der Datei /etc/php/7.3/mods-available/i-doit.ini bereits von 128M auf mittlerweile 2G geändert. (https://kb.i-doit.com/pages/viewpage.action?pageId=10223831#DebianGNU/Linux-PHP).
Nach dieser Änderung konnte ich den search-index-Befehl jedes mal ohne Fehler ausführen - am nächsten Morgen kam aber wieder der gleiche Fehler. Und wenn eine Erhöhung um das 16fache nicht reicht, wirkt es auf mich nach keinem normalen Verhalten. Womöglich besteht dies seit dem 1.17.1 Update - da bin ich mir nicht ganz sicher.
Hat jemand eine Idee woran es liegen könnte, was ich prüfen könnte?
Hatte diesen Fehler vorher nieSystem-Infos;
i-doit 1.17.1
Linux Debian VM -
Hi @jimwendrich
das Problem ist tatsächlich sehr merkwürdig, vor allem wenn man betrachtet wie "wenig" Daten indexiert werden. Gibt es ggf. andere Kategorien welche mehr Datensätze indexieren?
Hast du vielleicht ein paar Logs mit weiteren Informationen oder ggf. Stacktrace?
Alternativ würde mich auch mal interessieren wie groß der Index ist - du könntest hierzu auf der Datenbank die folgende Query ausführen:
SELECT COUNT(1) AS cnt FROM isys_search_idx;Anschließend könntest du den Suchindex neu aufbauen lassen und erneut die Größe auslesen... Eigentlich sollte sich diese nicht ändern
") Wächst sie allerdings kontinuierlich scheint es tatsächlich ein Problem zu geben!
Wächst sie allerdings kontinuierlich scheint es tatsächlich ein Problem zu geben!Viele Grüße
Leo -
@lfischer Hallo! Das waren super Tipps, ganz vielen Dank!
Also vorher:
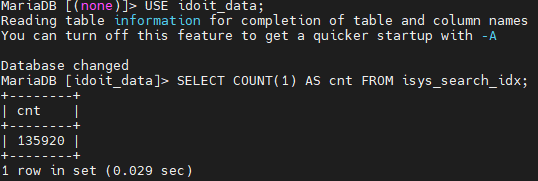
Und nachher:
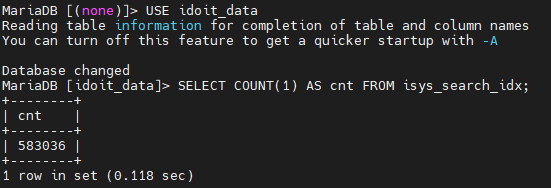
-> Beim ausführen dauerte der Punkt "JDISC Custom Attributes" Ewigkeiten. Dabei fiel mir ein, dass ich so etwas letztens einfach mal angehakt hatte im jdisc-import-Profil. Nämlich im Netzwerk-Profil:
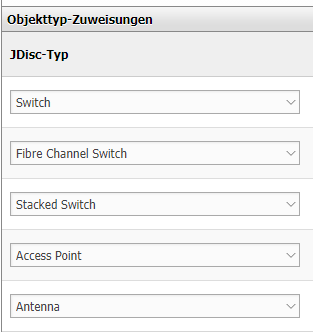
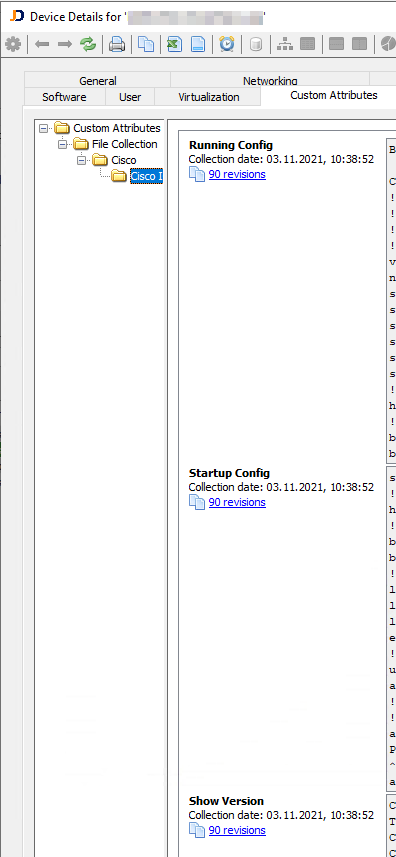
Bei einem Beispiel-Switch sind in der Kategorie Custom Attributes 1160 Einträge mit ner Menge Text(Running Configs etc) - kein wunder dass es so langsam ist/crashed. Damit habe ich beim setzen des Hakens natürlich nicht gerechnet.
Haben Sie einen Tipp wie ich das wieder bereinigen kann? Einfach den haken entfernen wird ja wahrscheinlich nicht reichen. Kann ich da eine Tabelle leeren in sql?
Vielen Dank schonmal, nun weiß ich zumindest woran es liegt.
-
Vielleicht sind noch ein paar Zahlen interessant:
Kategorie : Einträge
C__CATG__NETWORK_PORT: 50.000
C__CATG__GLOBAL: 80.000
C__CATG__MODEL: 32.000
C__CATG__DRIVE: 52.000
C__CATG__JDISC_CA: 434.000
C__CATG__IDENTIFIER: 27.000Betroffen sind circa 70 Switche, und ich würde nur ungern jeden einzeln öffnen und die Daten wieder rauslöschen. Trotzdem irgendwie komisch, dass aus 90 Revisionen der Running-Config, Startup-Config und Show-Version circa 1200 Kategorie-Einträge je Switch resultiert. Sieht fast so aus als würden diese täglich importiert werden (nicht nur die neuen)
Hier noch ein Bild aus JDISC:
-
Hey @jimwendrich
habe ich das bei das richtig gesehen / verstanden das der Suchindex um mehr als das vierfache "gewachsen" ist? Wie verhält sich das bei weiteren Indizierungen?
Wenn ich mich richtig erinnere haben die "Custom Attributes" von JDisc schon öfters mal für solche Probleme gesorgt, da hier einfach unglaublich viele Daten übertragen bzw. nachträglich auch indexiert werden... Hier kann ich nur empfehlen den Aufruf des Suchindex Commands anzupassen - hier lässt sich mittels
--categoryOption festlegen welche Kategorien indexiert werden sollen.
Das bedeutet du hättest einen einmaligen initialen Aufwand sämtliche Kategorien aufzulisten... Der Vorteil ist aber natürlich das du dann genau die Daten indexieren lässt die für dich interessant sind (= weniger Datenmüll und bessere Performance)!Dann musst du auch nicht nachträglich die ganzen Daten aus den Switchen löschen - die werden einfach nicht mehr indexiert
")
Ich hoffe ich konnte dir damit weiterhelfen!
Viele Grüße
Leo -
@lfischer Hallo, erstmal vielen Dank für die ausführliche Antwort.
Ja, das hast du richtig gesehen! Habe den Netzwerkimport gestern danach noch einmal manuell ausgeführt. Nach weiterer anpassung des memory_limit Wertes(4G) zeigte sich dieser Suchindex-Count:
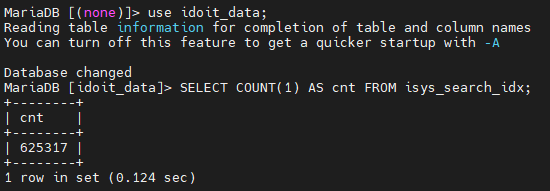
Habe die Kategorie JDISC Custom-Attributes danach wieder aus dem Netzwerk-Import entfernt. Nachdem ich den Netzwerk-Import eben manuell ausgeführt habe, hat sich der Suchindex nicht verändert, so wie es sein soll.
Also 1. Problem(BUG): Beim JDISC-Import der JDISC Custom Attributes werden die 270 Datensätze bei Switchen jedes mal zusätzlich importiert, anstatt nur jeweils die neu gescannten Datensätze! (Bei mir waren nach ein paar Tagen je Switch ~1200 Einträge in der JDISC Custom Attributes Kategorie, welche Standardmäßig natürlich auch für die Suche indiziert wird.Die Idee mit der Kategorie-Whitelist für den such-index ist sicher eine Idee Wert, aber natürlich nur Pfusch am Werk, bzw. es löst das Problem nur in vorm eines übergeklebten Tape-Klebebands. (Am Rande gesagt als Feature-Feedback wäre eine Blacklist hier in meinem Fall deutlich sinnvoller. Für das manuelle Eintragen habe ich keine Zeit - vielleicht gibts ansonsten eine Möglichkeit alle "aktiven" Kategorie-Bezeichnungen zu exportieren?)
"Dann müsste ich die Daten aus den Switchen nicht rauslöschen" - da möchte ich wiedersprechen. Es sind ja trotzdem VIEL zu viele Kategorieeinträge, (die mit der zeit veralten) - und wenn wir schon beim Thema "weniger Datenmüll" sind, ist es natürlich essentiell wichtig diese Daten wieder zu löschen.
Frage: Gibt es eine Möglichkeit alle Einträge der Kategorie JDISC Custom Attributes zu löschen? Vielleicht auf Datenbank-Ebene? (Beim search-index-Befehl wird auf die Tabelle isys_catg_jdisc_ca_list Bezug genommen)Freue mich über weitere Hilfe/Antworten.
-
Habe die Kategorie-Einträge in den ~70 Switchen mit einem Kollegen nun doch manuell gelöscht. Search Index erneuert:
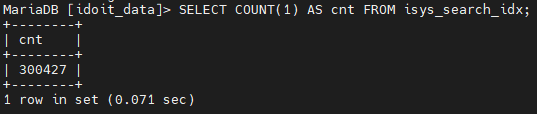
Das einzige was mich wundert, ist dass hier 300.000 Einträge sind, und vorher ~135.000. Aber vielleicht war das ja auch nur der Part bis zum Error
Die Suche scheint wieder schneller zu funktionieren. Die anderen Fragen dürfen Sie natürlich gerne trotzdem beantworten @LFischer
-
Hey @jimwendrich
ich habe eben einen Kollegen gefragt - der Bug bzgl. den "JDISC Custom Attributes" ist bekannt, aber es gibt noch keinen Fix dafür. So wie es aktuell aussieht wird es auch nicht mehr den Weg in die i-doit 1.17.2 finden.
Die Anmerkung zur White- bzw Blacklist verstehe ich sehr gut. Ich werde das mal mitnehmen, ggf. bekommen wir hier in der Zukunft eine zufriedenstellende Lösung hin
Wenn ich es richtig sehe sollte es (ohne Seiteneffekte) möglich sein die DB Tabelle
isys_catg_jdisc_ca_listzu leeren. Vorher aber bitte unbedingt eine Sicherung machen!Zum letzten Punkt: es kann natürlich sehr gut sein, das die zusätzlichen ~135k Einträge auftauchen weil der Prozess vorher abgebrochen ist... Ich fürchte das kann man nicht wirklich nachvollziehen

Viele Grüße
Leo -
@lfischer Alles klar, vielen Dank! Dem habe ich nichts hinzuzufügen. Dann kann das Thema geschlossen werden
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login